How it works
Toree provides an interactive programming interface to a Spark Cluster. It’s API takes in code in a variety of
languages and executes it. The code can perform Spark tasks using the provided Spark Context.
To further understand how Toree works, it is worth exploring the role that it plays in several usage scenarios.
As a Kernel to Jupyter Notebooks
Toree’s primary role is as a Jupyter Kernel. It was originally created to add full Spark API support to a Jupyter Notebook using the Scala language. It since has grown to also support Python an R. The diagram below shows Toree in relation to a running Jupyter Notebook.
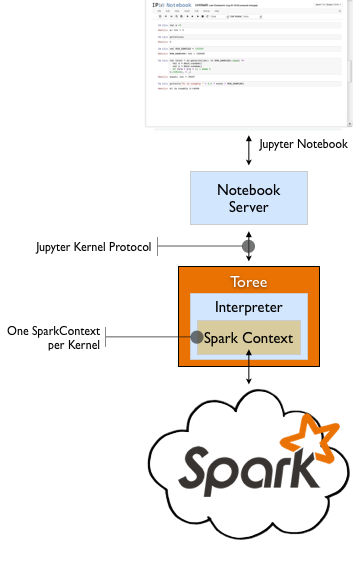
When the user creates a new Notebook and selects Toree, the Notebook server launches a new Toree process that is configured to connect to a Spark cluster. Once in the Notebook, the user can interact with Spark by writing code that uses the managed Spark Context instance.
The Notebook server and Toree communicate using the Jupyter Kernel Protocol. This is a 0MQ based protocol that is language agnostic and allows for bidirectional communication between the client and the kernel (i.e. Toree). This protocol is the ONLY network interface for communicating with a Toree process.
When using Toree within a Jupyter Notebook, these technical details can be ignored, but they are very relevant when building custom clients. Several options are discussed in the next section.
As an Interactive Gateway to Spark
One way of using Spark is what is commonly referred to as ‘Batch’ mode. Very similar to other Big Data systems, such as
Hadoop, this mode has the user create a program that is submitted to the cluster. This program runs tasks in the
cluster and ultimately writes data to some persistent store (i.e. HDFS or No-SQL store). Spark provided Batch mode
support through Spark Submit.
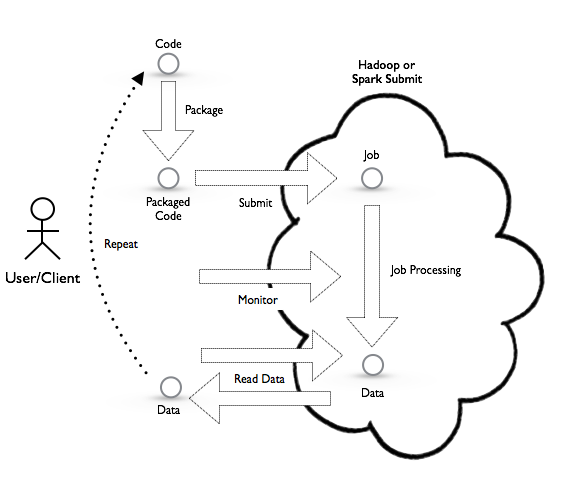
This mode of using Spark, although valid, suffers from lots of friction. For example, packaging and submitting of jobs, as well as the reading and writing from storage, tend to introduce unwanted latencies. Spark alleviates some of the frictions by relying on memory to hold data along with the concept of a SparkContext as a way to tie jobs together. What is missing from Spark is a way for applications to interact with a long living SparkContext.
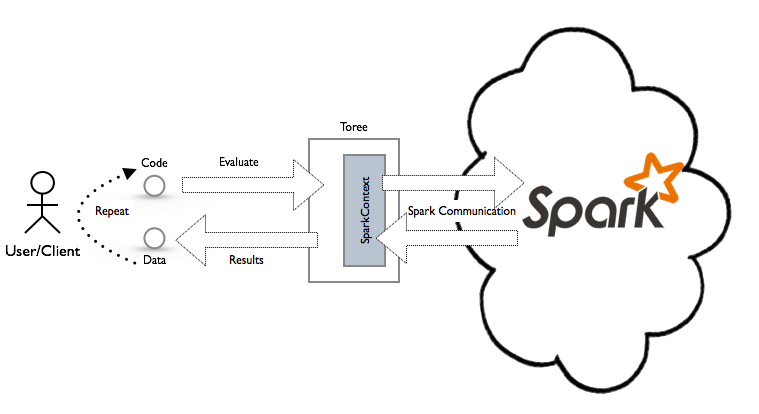
Toree provides this through a communication channel between an application and a SparkContext that allows access to the entire Spark API. Through this channel, the application interacts with Spark by exchanging code and data.
The Jupyter Notebook is a good example of an application that relies on the presence of these interactive channels and
uses Toree to access Spark. Other Spark enabled applications can be built that directly connect to Toree through the
0MQ protocol, but there are also other ways.
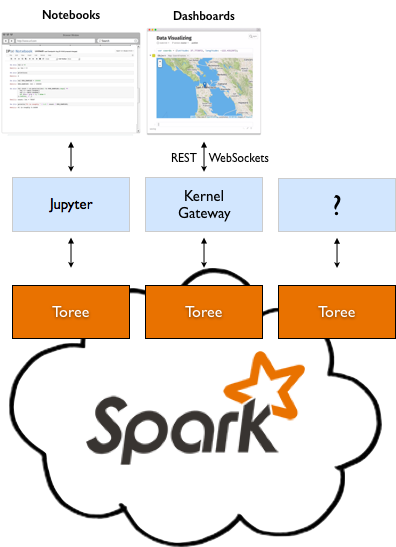
As shown above, the Jupyter Kernel Gateway can be used to expose a Web Socket based protocol to Toree. This makes Toree easier to integrate. In combination with the jupyter-js-services library, other web applications can access Spark interactively. The Jupyter Dashboard Server is an example of a web application that uses Toree as the backend to dynamic dashboards.